We archived 84 million tweets to learn about the pandemic – each one is a tiny historical document
During the pandemic, researchers have treated Twitter as a sprawling and evolving historical document.
- 22 June 2021
- 5 min read
- by The Conversation

The first tweet that the UK’s Department of Health and Social Care published about its new coronavirus testing regime came on January 25 2020. Less than a week later, the department tweeted its first announcement of two positive tests for COVID-19 in the UK, foreshadowing a chain of events that would have a profound effect on people’s lives.
As the coronavirus spread, these initial tweets were joined by millions of others, as people reacted to panic buying, rumoured lockdowns and heart-wrenching stories from across the world.
Soon, tweets about masks, the R number and herd immunity were competing with misinformation and conspiracy theories as the country “doomscrolled” through Twitter. Eventually, tweets about loo roll would be replaced by tweets about the rollout of vaccines worldwide – and the long-awaited roadmap back to normality.
Taken together, these tweets are a sprawling historical document – a modern-day diary of Samuel Pepys – revealing how life has changed during the pandemic. But with millions of tweets to sift through, making sense of them all requires careful archiving.
My colleagues and I have performed this archiving, creating a publicly accessible database of pandemic-related tweets that anyone can access. We hope the archive will help researchers and the public make sense of all that’s changed since the early weeks of 2020.
Twitter as research tool
Twitter is already regularly used as a research tool. One particularly interesting study revealed how early warning signs of COVID-19 spreading in Europe, signalled by an uptick in the use of words like “pneumonia”, were on Twitter as early as January 2020.
In other work, researchers have examined how world leaders turned to Twitter during the pandemic, and others have created datasets to expose how the public perceived their COVID-19 policies. Another dataset, from the University of Southern California, contains 123 million tweets, covering English, French, Thai, Indonesian and more.
Have you read?
Then came studies of misinformation on Twitter, which has been a key concern since the start of the pandemic. One study found that completely false claims spread faster than tweets with partially false claims. Another study found that unverified personal Twitter accounts featured the highest rate of COVID-19 misinformation, and that hashtags like #ncov2019 were more likely to be used in misinformation tweets than #Covid19.
Misinformation has also led to the emergence of conspiracy theories. Investigation shows they claim the virus was developed as a biological weapon, that the vaccination programme is a front for a mass surveillance programme, and even that the entire pandemic is a hoax.
These findings helped pressure social media companies to ban persistent offenders, remove misinformation tweets, hire more fact checkers, and add warnings to disputed information.
Archiving Twitter
As useful as all these studies are in capturing public opinion and encouraging platforms to moderate misinformation, most of their datasets are not publicly accessible and you need special skills to access and analyse them.
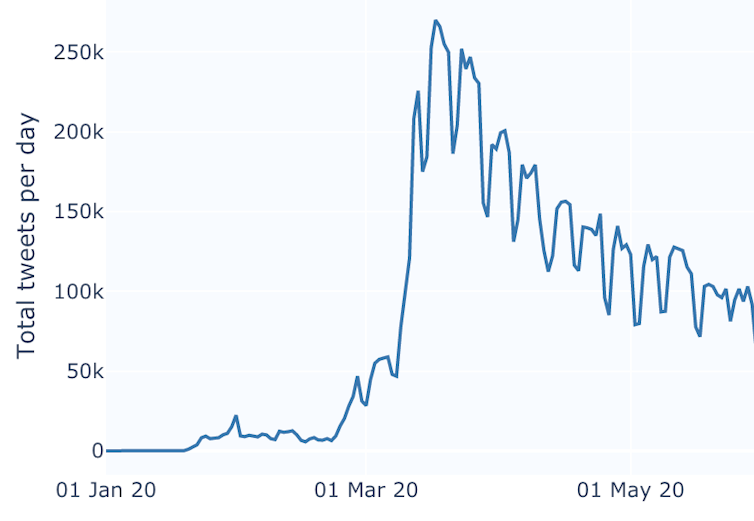
To address this barrier, our team at Birmingham City University has developed the Trust and Communication: Coronavirus Online Visual Dashboard (TRAC:COVID). It’s a collection of over 84 million tweets in English that contain words and hashtags related to the pandemic. It currently covers UK tweets from January 2020 to April 2021, and will be extended as we acquire more data.
TRAC:COVID is built on methods from a discipline known as corpus linguistics, which uses software to research a large body of text, known as a corpus. A corpus can be any size, but many of the largest online corpora contain millions or even billions of words.
Corpus linguistics has recently been used to analyse healthcare communications, from work on NHS patient feedback to understanding representations of obesity in the British press.
One of the main benefits of corpus linguistics is that it helps us quickly analyse millions of words, allowing researchers to develop deeper insights compared to manual inspection.
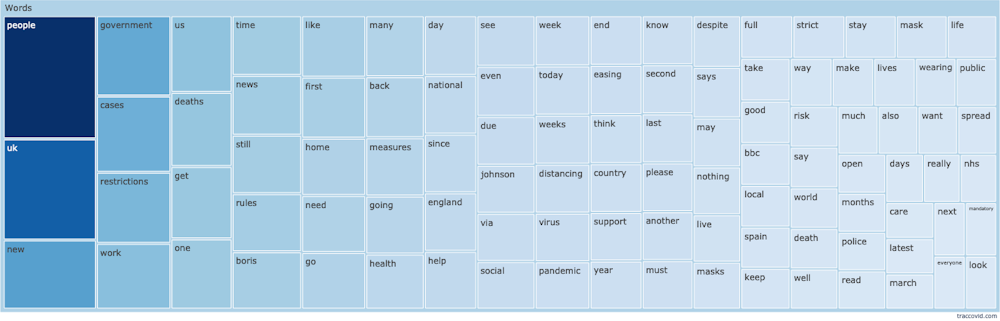
Since our corpus covers a specific period, users can chart how language use changed during the pandemic, how particular words have acquired new meanings, or when certain words stop being used altogether – all without requiring specialist knowledge or language analysis skills. Pulling these different strands together, we can build a detailed timeline of how conversations about COVID-19 have changed.
Reducing vaccine hesitancy
Our Twitter archive could also help us tackle ongoing issues related to the pandemic. Chief among them is vaccine hesitancy, which studies have shown to be fuelled by misinformation shared on platforms such as Twitter.
Using the TRAC:COVID archive, we’ve investigated vaccine-related tweets to get an idea of the scale and diversity of “anti-vax” stances on Twitter. While the most frequent hashtags were generally positive, such as #vaccineswork and #getvaccinated, we found several hashtags that spoke to different communities of anti-vaxxers.
The diagram below illustrates how these anti-vax discourses intersect with conspiracy theories and bunk science, exposing how anti-vaxxers are part of a broader constellation of fringe beliefs.
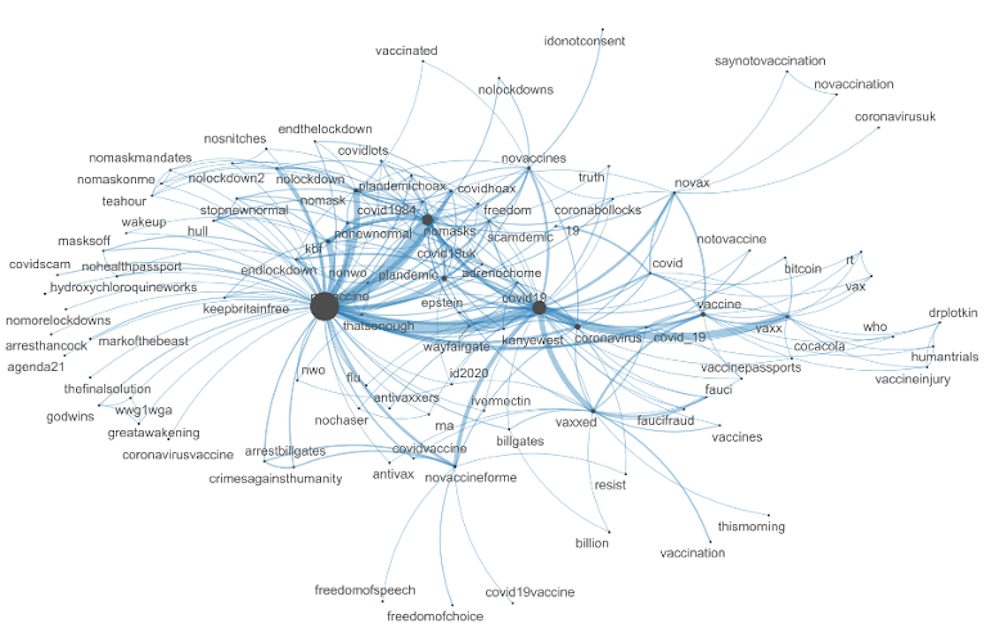
In extreme cases, these beliefs can cause widespread medical harm. For example, the UK has seen an increase in children contracting measles and mumps due to a growing number of parents choosing not to have their children vaccinated because of the fraudulent suggestion that the MMR vaccine causes autism.
Tweets about COVID-19 represent an important cultural artefact, charting how conversations and concerns about the pandemic have shifted over time. With our new resource, people will be able to explore a giant archive of pandemic perspectives, deepening their understanding of what preoccupied UK Twitter users during a unique period of world history.
Authors
Robert Lawson, Associate Professor in Sociolinguistics, Birmingham City University
![]()
This article is republished from The Conversation under a Creative Commons license. Read the original article.
Disclosure statement
The research featured in this article was a collaboration between Dr Andrew Kehoe (Principal Investigator), Dr Tatiana Tkacukova, Dr Mark McGlashan, Dr Robert Lawson, Dr Selina Schmidt, and Mr Matt Gee. Funding was received to develop TRAC:COVID from the Arts and Humanities Research Council as part of UKRI’s Covid-19 research programme.
Partners
![]()
Birmingham City University provides funding as a member of The Conversation UK.
More from The Conversation




Recommended for you